Voici les ressources nécessaires à tout développeur francophone qui veut se plonger dans la technologie Zope avec la meilleure efficacité :
Archives de catégorie : Open source
Plone va au COMDEX
Le produit de gestion de contenu Plone a été désigné par “la communauté open source” comme étant le logiciel libre méritant le plus d’être présenté au salon informatique américain COMDEX (Las Vegas). L’éditeur O’Reilly lui offre donc un stand. Suite à cet événement, les lecteurs de Slashdot évoquent les attraits principaux de Plone, ainsi que de Zope, le serveur d’application Python sous-jacent. De tous les serveurs d’application du marché, Zope aurait la capacité de montée en charge “la plus transparente” : la technologie de clustering ZEO n’imposerait pratiquement aucune modification du code des applications. Zope fournirait une technologie de gestion de cache mature et une interoperabilité indubitable. Zope est comparé au noyau linux et Apache et représenterait un avenir important pour le logiciel libre en lui permettant notamment d’entrer dans l’univers applicatif (“move open source software ‘up the stack’ to higher levels”). L’interface utilisateur de Plone (en particulier dans sa version 2.0) serait exemplaire en termes de modularité et de respect des standards d’accessibilité. Elle incarnerait l’état de l’art en matière d’architecture Web et d’extensibilité.
Enfin, les commentateurs soulignent l’importance et la diversité de la communauté d’utilisateurs et de développeurs de Plone, qui dépasserait celle de toute autre logiciel libre de gestion de contenu. Selon l’un des lecteurs, l’un des meilleurs atouts de Zope et de Plone serait cette communauté et son enthousiasme ; cet enthousiasme serait un indicateur de la disponibilité du support technique autour de ce produit.
Le nombre de société de services informatique offrant du support sur les technologies Zope et Plone semble confirmer cet indicateur.
Votre CMS open source préféré ?
O’Reilly lance un sondage : quel est votre système de gestion de contenu open source préféré ? Allez voter.
Alternatives open source à MS Access
Il semblerait qu’il apparaisse enfin des alternatives open source à MS Access : Rekall (distribué sous licence GPL ici et lu et discuté sur Slashdot) mais aussi un module d’OpenOffice (il doit être bien caché car la dernière fois que j’ai rapidement testé OpenOffice, je ne l’ai pas trouvé). Tiens, tiens, amusant, le langage de script de Rekall est Python !
Pour mémoire, toujours en Python, les produits zetadb et Formulator, dans l’environnement Zope, pourraient bien servir à faire la même chose mais en version Web.
Caractéristiques du modèle open source
Cet article expose quelques caractéristiques du modèle open source : pas de coût de licence logicielle bien sûr, pas de dépendance à un fournisseur, choix élargi de fournisseurs de services, haute flexibilité/possibilité de personnalisation, stabilité accrue, moindre coût matériel (ne nécessite qu’un serveur intel pour linux et non des serveurs haut de gamme), cycles de développement plus rapides.
L’article cite également quelques autres caractéristiques mais qui sont à mon sens plus discutables : meilleure évolutivité, liberté de choix du rythme de déploiement des nouvelles versions, meilleure prise en compte de l’utilisateur final pour le développement de nouvelles fonctionnalités.
Le meilleur agrégateur RSS
Je tiens à jour ce carnet web, ok. J’ai besoin d’un ” RSS aggregator ” (agrégateurs d’actualités syndiquées au format RSS) pour pouvoir suivre les autres carnets web qui m’intéressent, ok. Mais quel agrégateur de news choisir ? J’ai essayé Amphetadesk… pas mal ! Mais pas vraiment utilisable dès que l’on a plus d’une vingtaine de blogs à suivre (en plus, il m’a eu l’air super gourmand en ressources machine). Même avec son add-on AmphetaOutlines, qui le rend vraiment plus ergonomique, ce n’est pas encore ça. J’ai donc essayé NewsGator : pouah, il a besoin d’Outlook (c’est un plug-in dans Outlook) ! Newzcrawler ? Mouais, pas mal, l’idée d’avoir Microsoft Agent qui lit mes news est séduisante mais cet idiot ne sait apparemment lire les news que lorsque je clique dessus alors que j’aurais espéré qu’il me lise tout un canal ou, encore mieux, un canal agrégé… Sinon, en open source, il y a bien FeedReader avec une fonctionnalité de découvertes de canaux RSS (similaire à celle d’AmphetaDesk ?) qui est séduisante, mais l’ensemble manque encore de fonctionnalités et d’ergonomie. A suivre peut-être la version 3 ?Ah, et puis, il y a aussi Pears qui est pas mal, open source, mais 1/ Pears nécessite l’installation préalable de Python et de bibliothèques Python supplémentaires, 2/ le développeur de Pears n’est pas satisfait de ces bibliothèques et envisage donc de refondre l’application pour lui donner une architecture plus proche de celle d’Amphetadesk (serveur déployé localement sur le poste de l’utilisateur). A suivre aussi…
Après quelques tâtonnements et essais d’agrégateurs, je pense avoir trouvé l’agrégateur qu’il me faut. Il s’agit de FeedDemon, logiciel commercial actuellement gratuit (mais bientôt payant à environ 30-40$ d’après l’auteur). FeedDemon marche bien, accepte un tas de formats de syndications, est convivial, multilingue, ergonomie en trois panneaux et propose notamment un peu de valeur ajoutée après l’agrégation : possibilité de mettre en place des filtres qui affichent les items de tous les canaux qui répondent à certains critères de recherche (comme les CMFTopics mais en plus simple). Bref, un logiciel sympa, efficace et prometteur.
N’empêche que l’avenir reste pour moi l’utilisation de plate-formes de gestion de contenu comme agrégateurs. Et notamment, l’utilisation de Plone comme aggrégateur de News. J’avais réussi à faire tourner CMFNewsFeed et Plone 1.0 pour faire de la belle agrégation. J’attends que Plone 2 soit distribué et que Doug Hellman mette à jour CMFNewsFeed pour s’assurer de la compatibilité avec Plone 2 (j’ai fait quelques essais avec Plone 2 beta 3 et CMFNewsFeed 1.2 mais ça déconne à plein tubes avec, en vrac : des problèmes de dépendances aux versions de Python, des bugs dans le support des proxies, plus des bugs de Plone 2 beta 3 tout court). Je m’y remettrai donc plus tard. Et, en attendant : FeedDemon !
Zope pour le workflow
Modèle économique de la GPL
Ce mémoire présente la dynamique de coopération qui a fait le succès du modèle open source incarné par la licence de distribution logicielle GPL. Comme l’indique ce mémoire, l’auteur d’un ouvrage distribué sous licence GPL s’interdit par le biais de cette licence de disposer d’une rente (retour sur investissement) lié au capital que représente l’ouvrage qu’il a créé. Le droit de la propriété intellectuelle, dont la finalité est l’accroissement de l’innovation intellectuelle, serait sensé établir un équilibre entre la motivation économique des auteurs et celle des consommateurs. Trop de protection des auteurs et ceux-ci disposeront de rentes élevées mais qui, par effet pervers, rendront l’innovation suivante plus difficile ou moins motivante économiquement. Trop peu de protection et les auteurs perdront leur motivation économique à innover. La licence GPL, s’inscrivant dans le cadre du droit de la propriété intellectuelle, implémente des règles de coopération qui pourraient permettre de retrouver l’équilibre nécessaire au développement de l’innovation.
La coopération, nouvelles approches.
Michel Cornu a publié un document sur les dynamiques relatives au travail collaboratif. Il y introduit des “lois de la coopération” :
Nous cherchons à favoriser l’émergence de comportements de coopération et le développement de résultats collectifs. Nous avons cherché pour cela à identifier plusieurs lois qui permettent d’agir sur l’environnement pour le rendre plus favorable à la réussite du projet.
Pour réaliser ces 3 actions sur l’environnement, le porteur peut s’appuyer sur des lois qui lui facilitent son travail. Ces quelques lois simples mais fondamentales sont décrites en détail dans les chapitres suivants.
La réconciliation de l’intérêt individuel et collectif est favorisée par :
* Un environnement d’abondance qui provoque des mécanismes de contrepartie collectifs (nous verrons que l’abondance est plus fréquente qu’on ne le croit généralement dans certains domaines).
* La mise en place d’une communauté qui multiplie les interactions multiples entre les membres.
* Une nouvelle façon d’évaluer les résultats a posteriori qui implique l’ensemble de la communauté.
Pour multiplier les possibilités sans qu’aucune ne soit critique il faut :
* Réduire les besoins de départ.
* Minimiser au maximum les tâches critiques pour pouvoir en garder la maîtrise.
* Avoir du temps devant soit pour maximiser les opportunités.
Les personnes passent à l’acte grâce à :
* La motivation par la reconnaissance, le plaisir et l’apprentissage.
* La minimisation des risques perçus.
* L’abaissement du seuil du passage à l’acte par la simplicité et la réactivité.
La coopération est obtenue en agissant sur l’environnement plutôt que par la contrainte des personnes.
Le monde actuel en perpétuel mouvement aide à façonner l’environnement pour arriver aux trois conditions qui facilitent la coopération :
* Réconcilier l’intérêt individuel et collectif
* Multiplier les possibilités sans qu’aucune ne soit critique
* Faciliter le passage à l’acte
Il introduit une nouvelle notion de la propriété :
La notion de propriété ne disparaît pas pour autant. Par exemple dans le développement de logiciels libres, assez souvent, une personne détient le droit d’intégrer les modifications proposées par tous. Raymond l’appelle le ” dictateur bienveillant. ” Mais tout le monde peut venir utiliser, copier ou redistribuer librement le logiciel produit collectivement. Tout le monde peut circuler librement sur le territoire du propriétaire et c’est justement cela qui lui donne de la valeur.
Et énonce les règles nécessaires au bon fonctionnement d’une économie du don :
Une économie du don émerge lorsque les biens communs sont abondants.
Celle-ci implique de nouvelles notions de propriété et d’économie.
Les échanges de bien immatériels conduisent normalement à une multiplication de la valeur et à leur abondance. Il est souvent possible de faire des choix qui poussent vers la pénurie ou vers l’abondance.
Il existe des règles du don qui si elles ne sont pas respectées conduisent à des déviations :
1. L’abondance doit être préservée et bien répartie
pour éviter le retour à une économie de la consommation
2. L’évaluation doit être globale et décentralisée
pour ne pas qu’un don particulier serve à écraser l’autre
3. La contrepartie ne doit pas être demandée à celui qui reçoit
pour éviter les dettes…
N’hésitez pas à lire et relire son document pour en savoir plus.
Ceci m’inspire quelques motivations qui pourraient amener des grands groupes privés à open sourcer (adopter une stratégie s’appuyant sur la redistribution en opensource) leurs développements informatiques internes lorsque ceux-ci ne sont pas stratégiques (hors du coeur de métier) :
- sauvegarder la connaissance de l’application : distribuer la connaissance pour pouvoir en bénéficier ultérieurement sous la forme de services de maintenance
- disposer d’une maintenance corrective à faible coût : si d’autres acteurs adoptent le code distribué ET si ils redistribuent leurs modifications (y compris leurs corrections), cela offre un retour sur investissement au distributeur initial
- disposer d’une maintenance évolutive à faible coût : pour les mêmes raisons que ci-dessus
- améliorer son image auprès d’une communauté d’informaticiens et, indirectement, auprès de la presse informatique
- renforcer des relations de collaboration gagnant-gagnant avec d’autres groupes similaires
- influencer l’organisation d’un marché de fournisseurs : en orientant les distributions de code, le Groupe informe les fournisseurs des attentes réelles des utilisateurs
- minimiser les risques des projets informatiques internes en soumettant certains de leurs aspects au regard critique de la communauté d’utilisateurs/développeurs du code distribué
La bibliothèque de code open source du gouvernement américain
Développement rapide (RAD) avec Zope
Le produit zetadb associé au serveur d’application Zope est sensé permettre de faire du développement rapide d’application Web à partir d’une base de données. L’idée de ce produit est la suivante :
- A l’aide de votre gestionnaire de base de données préféré (on pourrait utiliser Access par exemple), vous générez votre structure de données.
- Vous lancez zetadb dans Zope et lui indiquez où se trouve votre base de données puis répondez à ses questions au sujet de la manière dont vous souhaitez employer ces données.
- Grâce à vos réponses et à votre structure de données, zetadb créé dans Zope les objets correspondants à vos données et pouvez donc gérer vos données à travers ces objets.
- Vous pouvez utiliser ces objets pour générer des écrans Web (à l’aide de modèles ZPT) ou bien pour générer des rapports sous forme de document bureautiques (au format OpenOffice).
Des templates HTML propres : ZPT
Pour construire des applications Web, il convient d’isoler le mieux possible le code de présentation (mise en forme, affichage, graphisme, …) du code de logique (règles de contrôle, structures de données, traitements). C’est pourquoi de nombreuses technologies de templating existent : elles consistent à proposer un modèle de présentation (le template) qui puisse être entièrement et sans risques manipulé par un graphisme ignorant le code logique. C’est ensuite un moteur de templating qui fusionne le modèle de présentation produit par le graphiste ou l’assembleur de pages avec le code logique prouit par le développeur ou programmeur.
L’une des technologies de templating les plus abouties est celle du Template Attribute Language (TAL) qui est implémenté dans les Zope Page Templates (ZPT) mais existe également en Perl (PETAL), PHP (PHPTAL) et Java (JavaZPT). Pour comprendre ZPT, rien de mieux que la FAQ ZPT, cet article pour débutant en ZPT et ce tutoriel.
SPIP, Plone, CPS ou PHPNuke ?
Les solutions opensource de gestion de contenu (“web content management”) sont nombreuses, diverses et relativement matures. Parmi les plus répandues, on trouve des solutions fonctionnant en environnement PHP telles que SPIP et PHPNuke et des solutions tournant en environnement Zope (Python) telles que Plone et CPS. Ce comparatif présente les avantages et inconvénients de chacun de ces quatre produits.
Commercialisez vos logiciels open source
Discussion sur Slashdot au sujet des modèles économiques liés à l’opensource, résumé et extraits :
- Dans le monde des affaires, certains logiciels gagnent à être libres et d’autres à être fermés. Au cours de la vie d’un logiciel, il peut exister un instant critique à partir duquel le logiciel gagnerait à devenir ouvert ou, au contraire, à devenir fermé.
- Un logiciel gagnerait à être ouvert à partir du moment où il permet de gagner plus d’argent en services (installation, paramétrage, assistance, support) qu’en vente de licence.
- Peut-être vaut-il mieux commercialiser des services et des produits s’appuyant sur des logiciels libres plutôt que d’essayer de commercialiser les logiciels libres eux-mêmes (licences).
- Si je développe un logiciel à usage interne et spécifique (pas dans une optique de revente), j’ai en général intérêt à le distribuer sous une licence opensource : je gagne ainsi de la force de recette et de développement en constituant une communauté autour de ce logiciel.
- 1/ développez un logiciel, 2/ prospectez et “vendez-le” largement mais sous licence opensource, 3/ établissez des contrats de services avec vos clients satisfaits par le logiciel (formation, support, maintenance corrective, maintenance évolutive, …), 4/ distribuez-le publiquement sous licence opensource.
- L’idée de commercialiser un service de support sur un logiciel opensource est séduisante mais difficile à mettre en oeuvre. En effet, le principal besoin de support est ressenti au moment de l’installation voire avant le démarrage (démonstrations, avant-vente, …), c’est-à-dire avant que le client ait pu profiter du caractère gratuit de la licence pour s’approprier le produit. Il est alors difficile de vendre un service (trop prématuré).
- Certains aiment distribuer leur logiciel sous deux licences : d’une part sous licence opensource GPL (ce qui empêche l’utilisateur de revendre le produit) et d’autre part sous licence commerciale (afin de permettre à l’utilisateur de revendre le produit après modification ou extension des fonctionnalités). Mais ce modèle rend difficile voire impossible la constitution d’une communauté de développeurs ouvertes puisque les contributions de cette communauté, si elles se font dans le cadre de la licence GPL, ne pourront pas être inclues dans la version commerciale du produit (à moins que les développeurs ne cèdent leurs droits au “propriétaire” du produit).
- Certains produits sont d’abord distribués sous licence commerciale et seules leurs anciennes versions sont distribuées sous licence opensource. Même remarque que précédemment sur la difficulté d’organiser une communauté ouverte de développeurs.
- Les services à vendre autour d’une application web opensouce : 1/ hébergement spécialisé (service en mode ASP), 2/ vente de licences pour des modules et fonctionnalités avancées, 3/ services de conseil, d’assistance, de développement spécifique, d’intégration, 4/ support technique avancé, 5/ autres services (graphisme, …).
L’article qui avait provoqué cette discussion est disponible ici.
Zope en hausse d’après netcraft
zegor signale que d’après les statistiques de Netcraft, la part de marché de Zope augmente fortement et constamment, comme l’indique ce graphique :  .
.
ROPE = Rdflib + zOPE
He is doing it : trying to tie together Zope and the magic of RDF triples, with the help of a nice ROPE. Go for it, Reinout !
Persistence objet sur LDAP, avec mapping
- En Java, avec DSML (mais module non supporté) : http://castor.exolab.org/index.html
- En Python, d’après Industrie Toulouse : http://toulouse.amber.org/archives/2003/04/21/evaluating_objectrelational_migration.html puis http://toulouse.amber.org/archives/2003/06/26/applying_mapping_patterns_to_ldap.html
- En Python, encore : http://mail.zope.org/pipermail/zope/2003-March/132270.html
- La persistence en Python, mais y a-t-il une solution concernant LDAP comme support : http://www.orbtech.com/wiki/PythonPersistence
- Une abstraction de stockage (mais sans mapping ?) : http://www.meta-language.net/metastorage.html
- En Perl : http://spops.sourceforge.net/doc/SPOPS/LDAP.shtml
Survivre sans Windows
Y a-t-il une vie après Windows ? D’après ce patron de PME, oui, une entreprise peut non seulement vivre sans Windows mais aussi a tout intérêt à envisager de s’en passer.
En bref, le BSA a poursuivi cette PME de vente d’instruments de musique ; il a été choqué par l’attitude méprisante et “anti-commerciale” de Microsoft à son égard ; il a donné six mois à son équipe informatique pour abandonner Windows ; l’équipe informatique a choisi et déployé linux sur les 72 postes de travail de l’entreprise ; les utilisateurs se sont formés aux nouveaux outils de travail (Mozilla pour le Web, Evolution pour le mail et le groupware, OpenOffice pour la bureautique) ; l’entreprise a gagné de l’argent et continue à en gagner à chaque montée de version Windows.
En plus, le patron de PME qui n’y connaissait rien en informatique est devenu le symbole d’une success story pour amateurs de pingouins.
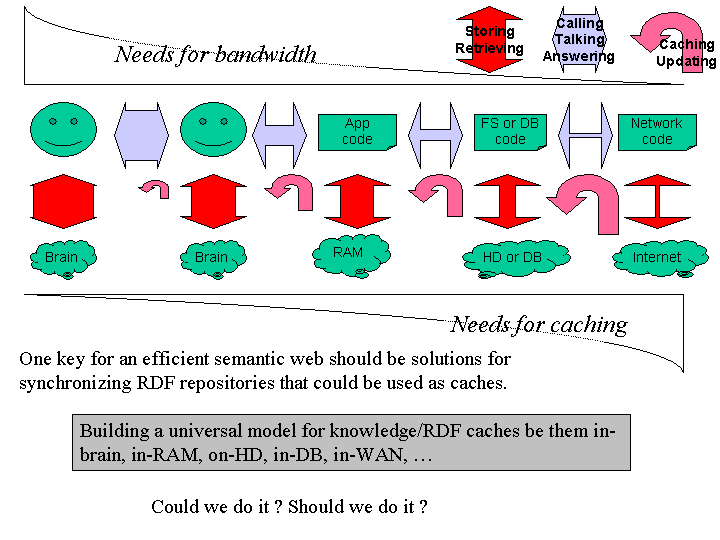
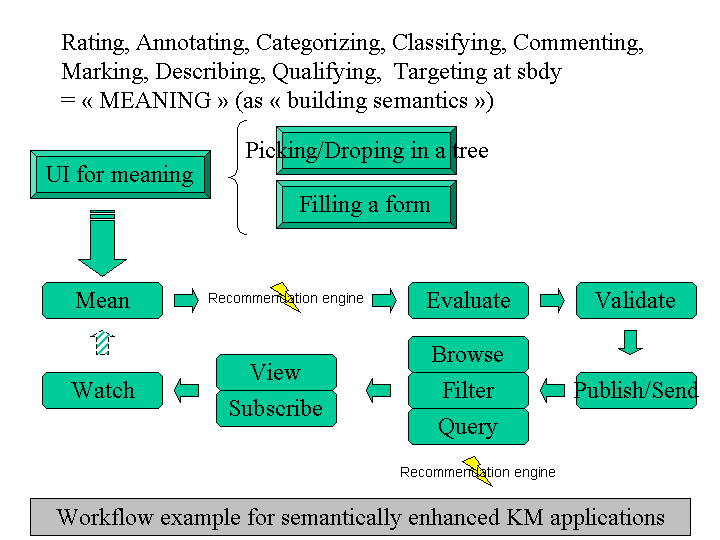
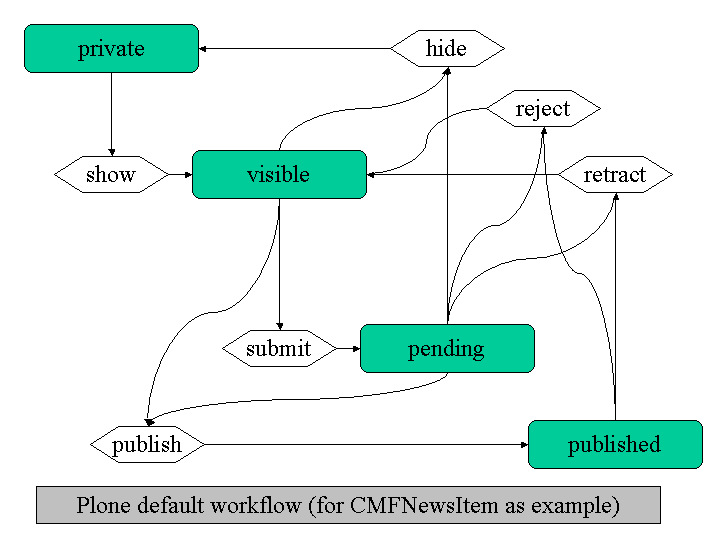
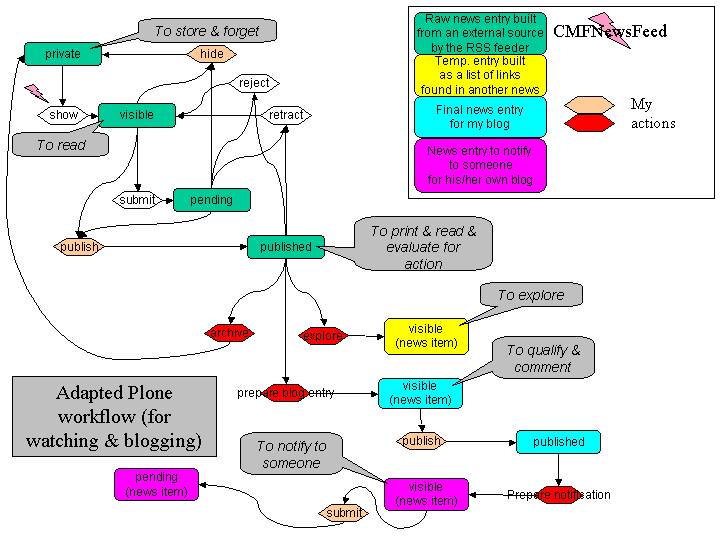
Plone-ing for the semantic web
Here is a little set of inconsistent slides about the future (Semantic Web) and the present (Plone) and how you can tie one with another. In a few words : there seems to be need for a universal model for knowledge/RDF caches ; the production/transformation of knowledge and content should go through a workflow ; Plone should ease the implementation of such a workflow. It’s all about some link between knowledge management and content management.
These slides are displayed below but are also available as a Powerpoint presentation.

Alternatives à J2EE
Pourquoi n’avez-vous pas FORCEMENT besoin de J2EE ? Jon Udell évoque des solutions alternatives à J2EE, en prenant un par un les arguments qui pourraient vous faire croire qu’hors J2EE, il n’y a point de salut :
- Scalabilité : que ce soit avec Java, sous Windows ou avec LAMP, il y a d’autres solutions de clustering et de répartition de charge que J2EE
- Fortement transactionnel : il existe toujours et encore CICS, Tuxedo, TopEnd ; de plus TP-Lite est une piste intéressante ainsi que le support des services web par les serveurs de bases de données
- Persistence relationnelle-objet : Castor, servlets avec JDO, l’EOF d’Apple, …
- Homogénéité = 1 seul environnement, 1 seul langage : même avec J2EE, les développeurs devront continuer à faire du SQL, des JSP, de l’XSLT… et des langages de scripting pour l’automatisation des traitements
Donc J2EE n’est pas la solution universelle à tous les problèmes. Fallait-il le préciser ?