Vous évoluez parmi les méta-données et autres normes RDFisantes ? Vous vous y perdez ? Mais avez-vous pensé à prendre avec vous le plan du métro ? Descendez-donc à la prochaine station du réseau MetroMeta, consultez-y le plan puis reprenez la ligne du web sémantique.
Archives de catégorie : Architecture
Ontology Works
“Ontology Works” fait partie de ces quelques éditeurs de logiciels pionniers dans l’intégration sémantique de données. Cette société commercialise une boîte à outils composée de :
- un environnement intégré de développement d’ontologies
- un “fédérateur” dont la fonction est de router des requêtes vers les différentes bases de données intégrées dans le dispositif, à la manière d’un “bus de connaissances”
- un système de base de données dit “déductif” (et non relationnel) privilégiant la flexibilité et le support des natifs des ontologies à la performance
- un générateur de schémas de données pour bases relationnelles de manière à rigidifier sous une forme performante (relationnel) un modèle de donnée incarnant des ontologies et donc accessible facilement depuis le “bus de connaissances”
- un “médiateur” rendant une base relationnelle existante accessible depuis le fédérateur de requêtes (bus)
Cette boîte à outils est un étrange mélange entre d’une part des outils ressemblant aux modélisateurs et générateurs de code à la Rational Rose et d’autre part des composants rappelant les moteurs de jointure et connecteurs des méta-annuaires.
Je regrette qu’il ne s’agisse que d’une boîte à outils “pour l’entreprise” qui suppose notamment que l’entreprise utilisatrice hiérarchise ses ontologies comme autant d’extensions locales d’une ontologie globale. Le dispositif n’est pas apparemment pas conçu pour faciliter le traitement des incohérences ou des contradictions entre ontologies. Par ailleurs, Ontology Works semble faire un usage abusif du terme “OWL”. Chez eux, OWL désigne un “Ontology Works Language” qui n’a peut-être rien à voir avec le “Ontology Web Language” du W3C. De plus, l’offre de cette société semble s’ancrer directement sur XML, sans passer par la case RDF. Ceci explique-t-il cela ?
Pour en savoir plus sur l’offre d’Ontology Works et les concepts tels que le “bus de connaissances”, l’intégration sémantique de données, les caractéristiques des bases de données déductives et le rôle de la gestion d’ontologies dans l’entreprise, la foire aux questions de cette société se révèle une source d’information très didactique.
How to aggregate news from wiki sites
Wiki engines often provide RecentChanges pages that list the wiki pages that were recently modified on a given site. These wiki engines progressively include a syndication feature that publish a RSS feed reflecting this RecentChanges content. But they may not implement syndication properly. Therefore, in a discussion about the ZWiki engine syndication feature, I posted the following enhancement request :
This is an enhancement suggestion for the RSS feeds above (I don’t
feel confident enough in my Zope/Zwiki skills to implement it right
now, and I am a little bit to lazy to do it…). My suggestion is
that, in these feeds, the URL of an RSS item should not be the URL of
the wiki page but the URL of the last historical revision of this
page.
Example : when the page MyPage has been modified, the RSS file should
not link to http://www.mysite.com/MyPage but to
http://www.mysite.com/MyPage/HistoricalRevisions/850.15891.51176.22809
Explanation : The current RSS feeds (see above) link to MyPage. Let’s
say that 5 users change MyPage in the morning of a given day. The
problem is that my RSS aggregator will check the RSS feed, let’s say,
once a day at noon. Then, my RSS aggregator will link to MyPage and
may provide a link to the latest diff of MyPage. It is OK. But, during
the afternoon, 5 additional users come and further change MyPage.
Then, when my RSS aggregator checks the RSS feed again (the day
after), it will not notice that further changes have happened to
MyPage ! The current RSS feed does not allow the aggregator to detect
that new changes have happened because the current RSS feed is not
using the proper resource. The current resource used is the page
itself whereas the paradigm of syndication/aggregation suggests that
the proper elementary resource is the message (the revision or the
diff itself). Or the users of aggregators may not be notified of
recent changes of the wiki resources. And wiki pages will only appear
in a given aggregator once during their whole life. Further changes
may be ignored by the aggregator (because it may say : “I already have
aggregated this URL before”) which is not a good thing and which is
not the fault of the aggregator !
What do you think ?
Another step toward a semantic wiki / bliki / bloki / wikilog
Le meilleur / le pire de la gestion de contenu
CMSWatch a établi une synthèse des principales fonctionnalités attendues pour un logiciel de gestion de contenu et a attribué des mentions aux principaux produits du marché. Pour prendre deux produits que je connais, voici ce qu’il en sort :
- Teamsite d’Interwoven : bon en “services de bibliothèques”, et en dynamisme du club des utilisateurs, mauvais en gestion des utilisateurs et des rôles, en gestion des métadonnées et des taxonomies
- Zope : bon en gestion des utilisateurs et des rôles, en indexation et capacité de recherche, en niveau de compétences des équipes de support, en “Good Value” (va savoir ce que ça veut dire…), mauvais en gestion des métadonnées et des taxonomies et en ergonomie
Un commentaire personnel : le fait d’avoir rangé Zope parmi les outils de gestion de contenu me semble démontrer une mauvaise connaissance de Zope, de la part de CMSWatch. En effet, Zope n’est pas un produit de gesion de contenu mais un serveur d’application (ou encore un environnement d’exécution). Certes, Zope est souvent utilisé pour construire des applications de gestion de contenu. Mais si CMSWatch avait voulu faire un travail vraiment professionnel, ils auraient noté Plone plutôt que Zope. Plone est effectivement un produit de gestion de contenu. Du coup, Plone n’aurait sans doute pas eu de point négatif en matière d’ergonomie puisque la qualité de son interface utilisateur est justement l’un de ses principaux points forts (sans compter tous les avantages du serveur Zope sous-jacent).
Semantic Wiki
This is an attempt to translate this other post into English
Charles Nepote, as he notified me, builta prototype of a wiki engine based on some of the semantic web technologies and providing some somewhat “semantic” features. I appreciated this prototype a lot. It lets me imagine how the wiki of the future would look like. Here are some pieces of a dream on this topic. The wikis of tomorrow would…
- …provide the semantic features of Charles Nepote’s prototype : complying to the REST style, one URL for every page, publishing both HTML and RDF representations of this page (it would be better to provide RDF within XHTML rather than beside, would’n it ?)
- … be Blikis (also known as Wikilogs) with pingback and/or trackback and so on
- …implement syndication of recent changes ; therefore they should produce distinct URLs for every update (every “diff” : as an example with URL like http://www.monsite.toto/2004/01/01/12/WikiPage for the 12th modification of the WikiPage, on 1st January 2004, whereas the URL of the WikiPage still remains http://www.monsite.toto/WikiPage).
- …“wikify” remote semantic data ; thus the page http://www.monsite.toto/DcTitle would contain a RDF statement (an OWL one ?) that would mean that this URL is the equivalent to the dc:title property of the Dublin Core
- …allow users to easily produce metadata with the help of an extension of the Wiki syntax ; as an example, when a WikiPage contains the statement “DcKeywords::MyKeyword”, the wiki engine automatically adds the RDF triplet with subject being the page itself (its URL), predicate being the URL of the “keywords” property as defined by the Dublin Core and object being the URL http://www.monsite.toto/MyKeyword.
- …have search engine allowing users to explore the Wiki with a navigation mode similar to sourceforge’s Trove Map based on the semantic data published by the Wiki ; as an example, the user will be able to display all the pages that are related to MyKeyword and are written in French (because they contain the RDF statements equivalent to the following explicit statement made by users within the page : DcKeyword::MyKeyword and IsWritten::InFrench)
- …have search engines allowing users to save their queries and explorations as agents (with their own WikiNames) so that other users can browse the same path of exploration as the user who defined the agent
I implemented these two last features as a draft of micro-application pompously called RDFNavigator for Zope, and base don the RDFGrabber product. It is very drafty so it is very incomplete, not documented, instable (because RDFGrabber is not particularly stable itself in my environement), so it may be difficult to make it run. Nevertheless, if someone dares trying it, I am eager to hear comments and critics ! :) By the way, I hope some day to make a more honorable product based on the integration of rdflib into Zope, i.e. based on Rope unless the Ticle project quickly provides a similar result within Plone.
Wiki Sémantique
Charles Nepote, ainsi qu’il me l’avait signalé, a réalisé un prototype de moteur de moteur de Wiki s’appuyant sur certaines des technologies du Web Sémantique et donc implémentant certaines fonctionnalités à caractère “sémantiques”. J’ai trouvé ce prototype particulièrement intéressant. Il me laisse entrevoir ce que pourraient être les wiki du futur. Voici quelques tranches de rêves à ce sujet. Les wiki du futur…
- …auront les fonctionnalités sémantiques du prototype de Charles Nepote : conformément au style REST, une URL pour chaque page associant représentation HTML et représentation RDF (il serait d’ailleurs préférable d’avoir le RDF dans du XHTML plutôt que à côté, dans une autre URL, non ?)
- … seront des Blikis (également appelés Wikilogs) avec pingback et/ou trackback et tout le tintouin
- …implémenteront la syndication des changements récents et, pour cela, produiront des URL distinctes pour chaque mise à jour de page (chaque “diff” : par exemple avec des URL du type http://www.monsite.toto/2004/01/01/12/WikiPage pour la douzième modification de la WikiPage, le premier janvier 2004, alors que l’URL de la WikiPage reste http://www.monsite.toto/WikiPage).
- …permettront de “wikifier” des données sémantiques distantes ; ainsi la page http://www.monsite.toto/DcTitle contiendra une donnée RDF (ou plutôt OWL ?) qui dira que cette URL est équivalente à celle de la propriété dc:title du Dublin Core
- …permettront aux utilisateurs de produire simplement des méta-données grâce à une extension de la syntaxe Wiki ; par exemple, lorsqu’une WikiPage contiendra la phrase “DcKeywords::MonMotClef”, le moteur wiki lui ajoutera automatiquement le triplet RDF ayant pour sujet la page elle-même (son URL), pour prédicat l’URL de la propriété keywords définie par le dublin core et pour objet l’URL http://www.monsite.toto/MonMotClef.
- …disposeront de moteurs de recherche internes permettant de les explorer avec le même mode de navigation que la Trove Map de sourceforge rien qu’en s’appuyant sur les donnéees sémantiques produites par le Wiki ; par exemple, l’utilisateur pourra afficher toutes les pages relatives à MonMotClef en ajoutant un filtre de manière à ce que n’apparaissent que les pages qui sont écrites en français (car elles contiennent quelque chose du genre IsWritten::InFrench)
- …disposeront de moteurs de recherche permettant à l’utilisateur d’enregistrer l’une de ses requêtes sous la forme d’un agent ayant son propre WikiName de manière à ce que d’autres utilisateurs puissent parcourir le même chemin d’exploration que l’utilisateur ayant défini l’agent
J’ai implémenté ces deux dernières fonctionnalités sous la forme d’un brouillon de micro-application pompeusement intitulé RDFNavigator pour l’environnement Zope, en me basant sur le produit RDFGrabber. C’est très brouillonesque donc très incomplet, non documenté, instable (car RDFGrabber n’est pas lui-même exemplaire en la matière) et donc difficile à faire tourner. Mais bon, si quelqu’un a le courage d’essayer, je suis friand de commentaires et critiques ! :) Par ailleurs, j’ai l’espoir un jour d’en faire un produit plus honorable en me basant sur l’intégration de rdflib dans Zope, c’est-à-dire sur Rope à moins que le projet Ticle ne fournisse rapidement un résultat similaire sous Plone.
Retour d’expérience sur la gestion de contenu
Content management, the hard way rapporte l’expérience de quelques consultants en gestion de contenu. Il part du constat de la désillusion actuelle des sociétés qui ont acheté, à grand frais, des solutions de gestion de contenu propriétaires, fermées et “sur-sophistiquées” (à la “Storyserver de Vignette” et autres “Teamsite d’Interwoven”). Ces sociétés utilisatrices ont constaté des coûts de maintenance exorbitants et des coûts de l’ordre de 20 000 euros par utilisateur et par an ! Et elles se sont retrouvées prisonnières d’une relation commerciale avec un éditeur sur la solution duquel elles avaient investi et dont elles peuvent aujourd’hui difficilement se débarasser.
Dans ce contexte, les solutions distribuées sous licence open source, telles que Red Hat CMS, OpenCMS, Zope et Plone ou encore MidGard paraissent séduisantes. Elles rencontrent déjà un succès commercial certain puisqu’elles ont conquis des références comme Siemens, la Banque Mondiale, le groupe Viacom, l’US Navy ou encore l’OTAN. Pourtant, le fait que la licence soit de type “open source” ne garantit en rien le succès du projet. Le type de licence garantit certes l’accès au code source, mais encore l’entreprise doit-elle veiller à ce que la solution choisie ait une architecture ouverte, évolutive et interopérable. Plus encore, l’entreprise doit veiller à disposer sur le marché d’une diversité suffisante de sources de compétences pour assurer le support de la solution : la solution considérée place-t-elle l’entreprise dans la même position de faiblesse vis-à-vis d’un fournisseur unique que dans le cas d’une solution commerciale ? ou bien existe-t-il suffisament de sociétés de services offrant des compétences solides sur ce produit ?
L’article mentionne également les tactiques des éditeurs de produits propriétaires pour contrer l’avancée de la gestion de contenu “open source” : former les commerciaux à discourir sur les faiblesses de ce nouveau type de concurrent, rappeler que l’open source a plus de succès en position de “suiveur” qu’en tant qu’innovateur (sic), affirmer que l’avenir de la gestion de contenu n’est pas la gestion de contenu Web mais le concept marketing de “gestion de contenu d’entreprise” qui, comme le précise l’article, relève plus du fantasme que la réalité.
En bref, les solutions propriétaires se sont déjà cassées les dents. Les solutions open source paraissent séduisantes mais ne sont pas une panacée pour autant.
RSS number One
L’article le plus apprécié de toute l’année, parmi les publications de O’Reilly, est celui qui présente le format de syndication RSS 1.0, conforme à RDF et extensible.
“Open sourcer” des développements spécifiques
Redistribuer des développements spécifiques sous licence “open source” (“open sourcer” des développements spécifiques) peut constituer une brique importante d’une stratégie informatique visant à se doter d’une architecture durable. Un témoignage sur Slashdot présente les arguments utiles pour convaincre une direction informatique du bien-fondé d’une telle démarche :
L’argument le plus simple pour la plupart des managers est du type : “vous bénéficiez du travail de N programmeurs mais vous ne payez le salaire que de M d’entre eux.” Et vous obtenez du test gratuit de certaines parties de votre produit. Vous pouvez également renforcer le soutien de la direction en mentionnant occasiollement : “Eh, je viens de resynchroniser nos modifications du package TRUCMUCHE, and j’ai vu que quelqu’un vient d’y ajouter le module TRUCBIDULE que nous justement l’intention de développer.” Cela donne à votre direction la douce et agréable sensation d’obtenir quelque chose à partir de rien.
Plus loin, il est ajouté, sur le même ton quelque peu cynique :
Dans de nombreux cas, bien sûr, contribuer au code open source ne faisait pas partie des intentions premières. L’idée d’origine était seulement d’utiliser un module pioché dans une archive quelconque. Mais parfois on découvre que le module ne fait pas exactement ce que l’on attendait de lui. Avec les logiciels libres, on peut résoudre ce problème. Et on donne ses modifications en retour, bien sûr. Ensuite, on en parle à la direction, qui hausse systématiquement les épaules et va s’occuper de quelque chose de plus intéressant. Si il y a débat, celui-ci peut être abrégé en rappelant quelque chose du genre : “Ce module nous a permis d’économiser plusieurs mois de développement ; passer un jour à résoudre un problème et à publier nos modifications est un petit prix à payer pour un tel bénéfice.”
Jon Udell complète ce témoignage par une analyse plus circonspecte de la situation :
Même lorsque les développeurs maison sont prêts à contribuer en retour, leur code (à juste titre) n’est pas toujours le bienvenu. ‘Le propriétaire d’un projet open-source froncerait les sourcils devant des modifications proposées par des personnes qui n’ont pas encore montré patte blanche […] Mais le développeur maison n’a ni le temps ni la disponibilité suffisante pour montrer patte blanche. Résultats : de multiples duplications maison (des “forks”) et la perte de ressources qui en résulte.”
Jon Udell rapporte également le terme de “releasability remediation” qui semble désigner l’activité consistant à rendre un code redistribuable au regard de la bureaucratie ambiante (restriction aux exportations, mesures de sécurité de l’entreprise, etc.).
Son article évoque ensuite diverses formes de contribution des entreprises aux projets open source dont elles bénéficient : publicité (via un bel enrobage dans des carnets Web, des discussions et des messages dans Usenet) et subventionnement de recherches académiques. La question qui reste ouverte est celle de la meilleure forme de contribution par l’entreprise à ces projets. Dans leurs commandes à leurs prestataires informatiques, les entreprises devraient-elles faire l’effort financier nécessaire à la redistribution de leurs développements spécifiques à base de logiciels open source ? Comment valoriser cet effort auprès de l’actionnaire et donc de la direction générale ?
Bliki, WikiLog
Le concept de Bliki ou de WikiLog désigne une famille de logiciels de contenu qui cumulent les fonctionnalités des Wikis et des WebLogs (ou carnets Web). On en parle ici en anglais et surtout sur le CraoWiki en français et plus en détails.
Mes idées du moment sur le comportement attendu d’un Bliki (je préfère Bliki à WikiLog, le mot condense mieux le concept) :
- Dans mon carnet Web, lorsque je publie un message qui contient un WikiName, celui-ci devrait être détecté automatiquement et transformé en lien pointant vers la page correspondant sur le Wiki associé à mon carnet Web. Si cette page n’existe pas, elle devrait être créée. Le Wiki associé devrait supporter la fonctionnalité de pingback et la fonctionnalité de trackback de manière à ajouter, en bas de la page du WikiName la mention et le lien de ce WikiName dans mon carnet Web.
- De même que les Wikis peuvent généralement afficher les “backlinks” d’un WikiName donné (la liste des autres pages Wiki dans lesquelles ce WikiName est mentionné), ils devraient permettre de rechercher ce WikiName dans un weblog donné voire dans Google.
- Lorsque quelqu’un veut ajouter un commentaire sur une WikiPage, le logiciel Wiki devrait lui proposer soit d’ajouter le commentaire dans le corps même de la WikiPage, soit d’ajouter son commentaire dans le carnet Web associé au Wiki, soit encore dans le carnet Web associé à l’utilisateur en cours (si celui-ci est identifié par cookie ou bien authentifié plus sûrement), soit enfin dans un carnet Web qui sera crée automatiquement pour cet utilisateur si celui-ci n’en dispose pas encore. Son commentaire sera ensuite lié en pingback et/ou en trackback depuis la WikiPage.
- Lorsque quelqu’un veut ajouter un commentaire dans un carnet Web, le carnet Web devrait lui proposer plutôt d’ajouter ce commentaire dans son carnet Web personnel voire lui proposer un assistant de création de carnet Web si l’utilisateur n’en dispose pas déjà d’un.
Pour résumer, afin de faire des Blikis, plutôt que d’inventer un nouveau type de logiciel “from scratch”, je suis partisan d’ajouter des fonctionnalités aux carnets Web et aux Wikis existant, en s’appuyant sur des spécifications ouvertes telles que le format classique des WikiName, les trackbacks et les pingbacks. Ces fonctionnalités seraient les suivantes :
- support des trackbacks et pingbacks dans les Wikis
- support des WikiNames dans les carnets Web
- afin de boucler la boucle des Blikis, ajout d’un assistant à la création de carnet Web lors de tout ajout de commentaire dans un Wiki ou dans un carnet Web
Les trackbacks dans WordPress
Dans WordPress, les URLs inclues dans un post sont automatiquement soumises à un “pingback” (ce qui cause parfois des timeout lors de la validation d’une nouvelle entrée, d’ailleurs). Mais les trackbacks, je n’avais jamais essayé. Alors faisons un test de trackback sur http://sig.levillage.org/index.php?m=200312#post-386 pour voir si ça marche bien.
Développement d’une architecture informatique durable
Les grandes entreprises ont besoin de stratégies informatiques, en particulier en matière d’architecture applicative. Voici donc une esquisse de stratégie architecturale.
- Objectifs stratégiques
- sécuriser l’environnement informatique : maintenir la sécurité de fonctionnement du système d’information, faire cesser la prolifération désordonnée des technologie, maîtriser l’incendie du e-business
- optimiser les économies : réduire les coûts sur le long terme, gagner en productivité
- bâtir un ordre social pour la communauté informatique : ordonner les investissements informatiques, se doter d’une politique, de règles d’architecture, de processus de contrôle, construire une communauté interne pour soutenir et faire appliquer cette politique
- => “triple bottom line” => comment assurer développement durable d’une architecture informatique ? une architecture “future-proof” ?
- Objectifs tactiques : construire une architecture applicative durable …
- … du point de vue économique : à moindre TCO = “scalable” (évolutivité, capacité à supporter des développements futurs à moindre coût), exploitable et maintenable (minimiser les coûts récurrents), à moindre investissement (licences logiciells, …)
- … du point de vue écologique : sûre et robuste quelles que soient les évolutions du reste de l’environnement informatique (sécurité, interopérabilité, portabilité, évolutivité), sobre en ressources (en ressources réseaux, en infrastructure), assurant une autonomie vis-à-vis de son environnement (indépendance vis-à-vis des politiques commerciales des fournisseurs, indépendante de l’évolution des métiers de l’entreprise, indépendante des évolutions de l’organisation de l’entreprise à moyen terme y compris acquisitions et cessions),
- … du point de vue social : appuyée sur un modèle de gouvernance durable, qui implique toutes les parties prenantes de la gestion des systèmes d’information (y compris les fournisseurs et éditeurs, les services utilisateurs, les équipes informatiques, la direction générale), offrant des ancrages de l’organisation dans des communautés locales et des réseaux de partenariat étendus (avec d’autres entreprises partenaires, avec les futurs gestionnaires de cette architecture, …)
- donc appuyée sur les principes architecturaux suivants :
- couplage faible et couplage tardif : les composants mis en oeuvre doivent offrir une modularité extrême, pouvoir évoluer indépendamment les uns des autres, être “agnostiques” sur l’usage qui sera fait des données qu’ils traitent ou produisent (de manière à en maximiser les opportunités de réutilisation), faire les hypothèses les plus réduites possibles sur les évolutions à venir du S.I., ne pas requérir de vision globale (ni d’étude globale) préalable à leur mise en oeuvre, supporter une dynamique d’évolution “en bazar” plutôt qu’ “en cathédrale”, s’assembler selon le modèle REST (REpresentational State Transfer) plutôt que selon le modèle RPC (Remote Procedure Call)
- l’architecture applicative est isolée des métiers : de même que la fonction financière de l’entreprise peut être rendue indépendante des spécificités de ses métiers, l’architecture applicative, pour être durable, doit être considérée comme indépendante des métiers d’entreprise ; sa portée est universelle dans l’entreprise ; son universalité offre des opportunités de benchmarking et de partenariat étendues avec les acteurs externes
- respect absolu des standards les plus ouverts possibles : qu’il s’agisse d’un standard de facto (informatique “legacy”, monopole commercial, …) ou de jure (spécifié par un organisme de normalisation), un standard est ouvert si :
- il “vient de l’Internet”, i.e. on peut observer un grand nombres de ses implémentations sur l’Internet, ses spécifications détaillées sont publiées sur l’Internet, la communauté qui l’a élaborée privilégie l’Internet comme mode de collaboration,
- il dispose d’implémentations nombreuses et diverses et l’une de ses implémentations est distribuée sous une licence de type “open source”,
- ses spécifications sont élaborées par une communauté ouverte : regroupant des acteurs d’origine et de taille diverses, avec une barrière à l’entrée très basse, et sachant tirer partie des contributions qui lui sont adressées sur la base de l’intérêt objectif de celles-ci et non de l’identité du contributeur
- Objectifs opérationnels
- contrôler l’architecture par le biais des relations fournisseurs : favoriser systématiquement la mise en concurrence des fournisseurs informatiques, n’acquérir une technologie que lorsqu’elle s’accompagne d’une offre de services supportée par une communauté de prestataires à la fois diversifiée (plusieurs sociétés de services) et dynamique (nombreuses références, nombreuses contributions), ne placer des fournisseurs en situation de monopole (contrats cadres) qu’à condition de préparer le changement futur de fournisseur (si les conditions contractuelles ne sont pas respectées ou bien, tout simplement, à l’issue du contrat), rester systématiquement dans une position de fermier (“je cultive ma terre”) plutôt que de métayer (“je cultive la terre du propriétaire”, en l’occurence celle de mon fournisseur), piloter les choix logiciels par les principes architecturaux (couplage faible et tardif, respect des standards)
- open sourcer l’architecture : c’est-à-dire externaliser les coûts de développement auprès de tiers par le biais d’une redistribution sous lience “open source” des adaptations spécifiques et développements maison, de manière à annuler les coûts d’investissements (pas de coûts de licences à l’achat) et de manière à mutualiser les coûts de développement et de maintenance avec des tiers (autres entreprises utilisatrices, sociétés de services informatiques, informaticiens indépendants) ; pour cela, redistribuer systématiquement les développements maison non stratégiques (non liés à un avantage concurrentiel certain) sous licence “open source”
- préférer les choix “juste-assez” aux choix “idéaux” (“le mieux est l’ennemi du bien”) : pour évaluer la disponibilité en compétences informatiques nécessaires à l’exploitation et la maintenance de la technologie nouvellement acquise, ne pas confondre la disponibilité suffisante de compétences et la disponibilité maximale de compétences ; appuyer le choix de nouvelles technologies à acquérir non pas sur leur degré absolu de sophistication (ce qui se paie en compétences d’exploitation) et de popularité médiatique (ce qui se paie en coût de licences et de support) mais sur l’adéquation entre celle-ci et le besoin qu’on en a ; si votre système d’information est urbanisé, préférer l’approche “citadine” à l’approche “4×4”
Conférences Zope et Plone au CNIT, La Défense
Portails open source
Le Journal du Net fait le point sur l’offre de produits de portail distribués sous une licence open source. Les produits évoqués dans cet article sont l’incontournable SPIP, le fameux Phpnuke (et ses dérivés), Glasnot, Lutèce et, bien entendu, dans la catégorie un peu plus “entreprise” (grosse) : Zope ou encore JetSpeed.
Gestion d’annuaire LDAP avec Zope
Deux applications Zope pour gérer le contenu d’annuaires LDAP : LuDAP de Makina Corpus, et NuxMetaDirectories de Nuxeo.
Workflow dans Plone
Ce document explique les phases du développement d’application de workflow s’appuyant sur Plone. Une fois Zope, Plone et CMFOpenflow installés, l’essentiel du travail consiste à modéliser le processus qu’il s’agit d’informatiser. Cette étape est critique car la modélisation de processus est en soit difficile. Elle requiert une grande rigueur et de bonnes compétences d’analyses fonctionnelles ainsi qu’une excellente communication entre l’analyste et le gestionnaire du processus. Une fois le workflow (modèle de processus) dessiné sur papier (analyse), il est facile de le transcrire dans OpenFlow. Ensuite, le développeur doit déclarer dans Zope les rôles utilisateur requis par le workflow puis aura à créer les formulaires de saisie de données de chaque étape du workflow ainsi que les éventuels scripts déclenchés lors des transitions entre étapes du processus. Un peu de test, et hop, ça tourne (du moins en théorie).
Il est bon de noter que la plupart des moteurs de workflows fournissent un éditeur graphique de Workflow. Cette interface semble extrêmement importante pour le novice qui examine ce type de produit. Cependant, il semblerait qu’un éditeur de ce type n’apporte pas grand chose de plus qu’une feuille de papier et un stylo. OpenFlow ne fournit pas d’éditeur de ce type mais seulement un visualisateur de workflow (une fois que les étapes du workflows ont été transcrites dans le paramétrage de OpenFlow). Cette lacune ne semble donc pas critique.
Plone a été initialement distribué avec un module de workflow “DCWorkflow”, orienté document. OpenFlow est un autre produit de workflow pour Zope qui diffère de DCWorkflow par le fait qu’il est orienté “activité” et permet donc de modéliser des processus plus complexes et moins spécifiquement liés à la gestion de contenu Web. Cependant, OpenFlow est un produit Zope qui ne s’appuie pas sur le framework CMF. Par conséquent, il était difficile de développer des applications de gestion de contenu faisant appel aux fonctionnalités avancées d’OpenFlow. C’est pourquoi la communauté de développement d’OpenFlow a créé Reflow (également appelé CMFOpenFlow, apparemment) qui, lui, est sensé s’intégrer parfaitement dans CMF et donc a fortiori dans Plone.
Développer avec les Archetypes
Archetypes est un produit Zope qui permet de développer des applications de gestion de contenu s’appuyant sur CMF (et sur Plone, par exemple). Une introduction didactique au fonctionnement d’Archetypes nous en explique le fonctionnement et la raison d’être : Archetypes permet au développeur de ne pas avoir à maîtriser la complexité (de l’API) du framework de gestion de contenu CMF, en lui permettant de générer de manière rapide des objets s’appuyant sur CMF. Archetypes constitue donc, en quelque sorte, l’essentiel d’un atelier de développement rapide d’applications de gestion de contenu.
Le principe général de fonctionnement est le suivant. Le développeur décrit en quelques lignes de Python le schéma de l’objet qu’il veut développer, en s’inspirant du schéma d’un objet existant : “ma classe d’objet ‘MonArticle’ a les mêmes propriétés et méthodes que les objets de la classe ‘Article’ mais possèdent également un champ de type texte, qui s’appelle ‘thème’, qui ne peut pas être vide et que l’utilisateur remplira à l’aide d’une ‘textarea’ HTML”. C’est ensuite le produit Archetypes qui transforme cette définition en un objet opérationnel qui peut être installé dans une instance Plone sans développement supplémentaire.
“L’informatisation des plus démunis depuis le début du 3ème millénaire”
Une association locale américaine, Free Geek, se fait un plaisir de transformer les plus démunis en accrocs de l’informatique : remise en état de matériel informatique, installation de logiciels open source, etc.
Apprendre Zope et Plone
Ceci est une traduction de mon message initialement posté en anglais.
On dit parfois que la maîtrise de Zope et de Plone est un art difficile. On a également dit que la courbe d’apprentissage pour Zope est particulièrement raide. J’ai également lu plusieurs débutants (comme moi) qui demandaient par où commencer pour se mettre au développement Zope. “Ne commencez pas à apprendre Zope sans connaître Python !”, “Inutile de maîtriser TAL, TALES et METAL pour construire des interfaces utilisateurs dans Plone, il vaut mieux apprendre les techniques de CSS avancées”, et d’autres réflexions du même genre… Alors je me demande : quelle est la progression recommandée pour apprendre Zope et Plone ? comment rendre la courbe d’apprentissage globale plus douce ou ne serait-ce qu’un peu plus visible et gérable ? Le diagramme ci-dessous représente ma compréhension de la “feuille de route d’apprentissage” idéale pour celui qui souhaiterait devenir un maître en Zope et Plone :
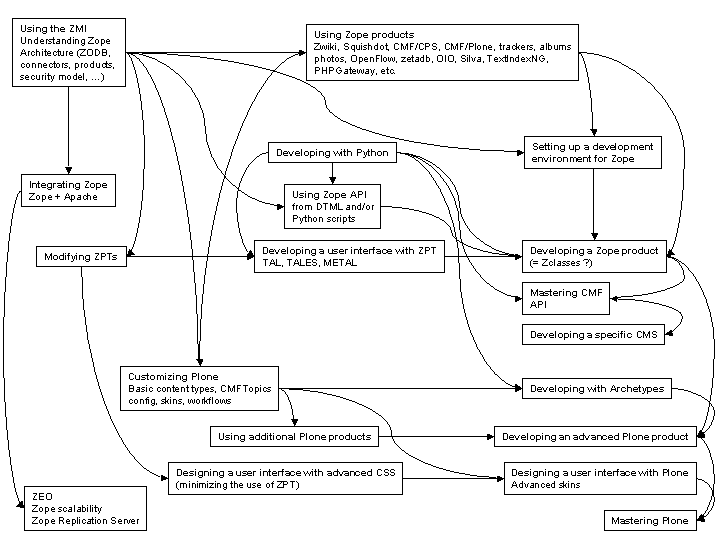
Zope and Plone learning roadmap
It is sometimes said that the art of mastering Zope and Plone is difficult. It has also been said that learning Zope Zen involves a steep learning curve. I have also read many newbies (like me) asking for information about the first steps to go through in order to smoothly get into Zope development. “Don’t start learning Zope before you know Python !”, “No need for mastering in TAL, TALES and METAL for building Plone user interfaces, you’d rather learn advanced CSS techniques”, or the like… So I wonder : what is the recommended roadmap for learning Zope and Plone ? how to make the global learning curve smoother or just a little bit more visible and manageable ? So the diagram below is my guess on the ideal learning roadmap for a would-be master in Zope+Plone :